![]()
![]()
![]()
![]()
One way to manage a large query load would be to copy the entire IQ database to multiple machines. Extra servers could each run the same database, but after changes at one of the servers, many of the files would have to be copied to the other servers again. Once the IQ Store became very large, you would have to purchase lots of extra disk capacity, and copying the database would take a long time.
IQ multiplex capability provides an effective alternative, where the IQ Store cost is reduced by sharing it, taking advantage of a shared disk subsystem. Sybase IQ's vertical storage, compression and bitwise technology reduce I/O requirements dramatically, making it possible to have many systems sharing the disk array(s) before contention degrades performance. You gain additional CPU power and memory space for processing queries by attaching more systems to the shared disk array. Multiplex capability lets a user perform loads while other users query the database.
Figure 1-1: IQ multiplex architecture
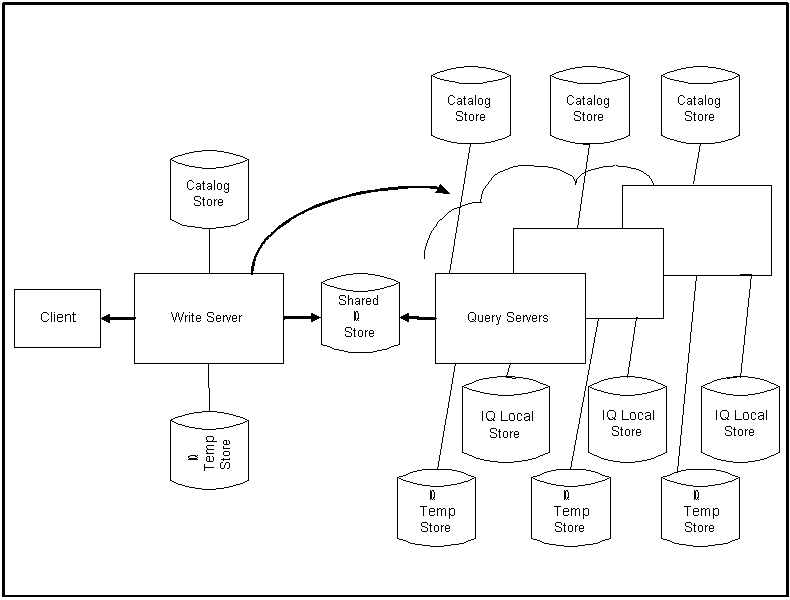
Each set of an IQ Temporary Store and Catalog Store comprise one server.
In an IQ multiplex, one server can load or update the database while the others submit queries. The read-only servers submitting queries are called query servers. The updating server is known as the write server. By allowing only a single write server, Sybase IQ multiplex eliminates the overhead and scalability limits of a distributed lock manager.
Each server of a multiplex may start, stop, and operate independent of all the others. Failure of any server does not prevent the other servers from operating. There is no need to stop a write server. Query servers should only be stopped in extraordinary circumstances:
Configuring a new write server
Restoring the query server from backup
Performing forced recovery/drop leaks on the query server
Starting the write server in single-node mode
The servers share a common IQ Store. Users may also create an IQ Local Store on each query server, in which they can create and store persistent objects. Such objects are visible to all users of that query server, but not to users on other servers of the multiplex. For details see “Populating persistent tables in multiplex databases”.
The following sections provide more details about multiplex operation:
