![]()
![]()
![]()
![]()
A text node is a hierachical tree data structure that maps byte offsets (and character offsets for multibyte servers) to text pages for text data. Text nodes are used for:
Text-page prefetch
Indexing to text or image data when starting offsets are specified for readtext()
Each entry in the text node points to the text or image data page where a byte offset (or character for multibyte servers) begins. Using this data structure, when given an offset into text/image data, the starting page can be determined, and the text or image data is read starting at that offset. This eliminates the need of having to start at the beginning of the text or image data and discarding all of the data the comes before the offset.
Text nodes take advantage of the fact that text or image data pages are typically allocated with multiple runs of consecutive page numbers. This means there does not need to be a one to one correspondence between the pages allocated to the text or image data, and the number of entries in the text node, which results in reducing the number of pages that are allocated to the text or image data.
Figure 1-3 describes this compression:
Figure 1-3: How text or image page numbers are allocated
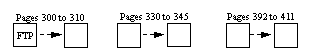
In this example, the text or image data is made up of 87 text or image pages, but because there are three separate runs of consecutive page numbers, (300 to 310), (330 to 345), and (392 to 411), only three text node entries are needed, not 87.
The text node is saved with the text or image data. Depending on the size of the text node, extra text or image pages may be required to store the text node. The size of the text node depends on the size of the text or image data, and the amount of 'compression' achieved. Although smaller text nodes do not require extra text or image pages, larger text nodes will require them.
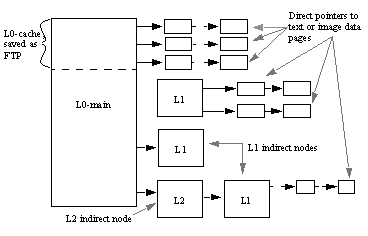
The head of the text node, the L0-cache, is stored on the FTP.
Figure 1-4 describes the structure of a text node. L0 cache is the text node, and L1 and L2 are indirect nodes that point to text or image data pages.
Figure 1-4: Structure of the text node