![]()
![]()
![]()
![]()
An index hash-based scan can be performed using either a nonclustered index or a clustered index on a data-only-locked table. To perform the scan:
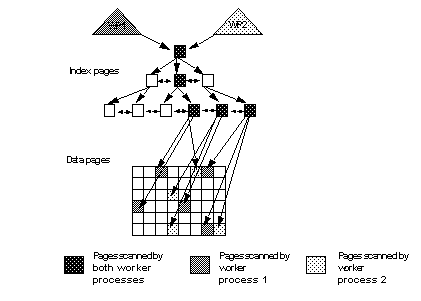
All worker processes traverse the higher index levels.
All worker processes scan the leaf-level index pages.
For data-only-locked tables, the worker processes scanning the leaf level hash on the page ID for each row, and scan the matching data pages.
For allpages-locked tables, a hash-based index scan is performed in one of two ways, depending on whether the table is a heap table or has a clustered index. The major difference between the two methods is the hashing mechanism:
For a table with a clustered index, the hash is on the key values.
For a heap table, the scan hashes on the page ID.
Figure 25-4 illustrates a nonclustered index hash-based scan on a heap table with two worker processes.
Figure 25-4: Nonclustered index hash-based scan