![]()
![]()
![]()
![]()
Statistical aggregates are similar to the avg aggregate in that:
The syntax is:
var_pop ([all | distinct] expression)
Only expressions with numerical datatypes are valid.
Null values do not participate in the calculation.
The result is NULL only if no data participates in the calculation.
The distinct or all clauses can precede the expression (the default is all).
You can use statistical aggregates as vector aggregates (with group by), scalar aggregates (without group by), or in the compute clause.
Unlike the avg aggregate, however, the results are:
Always of float datatype (that is, a double-precision floating-point), whereas for the avg aggregate, the datatype of the result is the same as that of the expression (with exceptions).
0.0 for a single data point.
Figure 2-1: The formula for population-related statistical aggregate functions
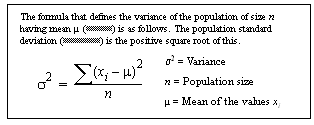
Figure 2-2: The formula for sample-related statistical aggregate functions

The essential difference between the two formulas is the division by n-1 instead of n.
These two functions are similar, but are used for different purposes:
var_samp – is used when you want evaluate a sample—that is, a subset—of a population as being representative of the entire population
var_pop – is used when you have all of the data available for a population, or when n is so large that the difference between n and n-1 is insignificant
