![]()
![]()
![]()
![]()
The NARY
NESTED LOOP JOIN strategy is never evaluated
or chosen by the optimizer. It is an operator that is constructed
during code generation. If the compiler finds series of two or more
left-deep NESTED LOOP JOINs,
it attempts to transform them into a NARY NESTED
LOOP JOIN operator. Two additional requirements
allow for transformation scan; each NESTED LOOP JOIN operator
has an “inner join” type and the right child of
each NESTED LOOP JOIN is
a SCAN operator. A RESTRICT operator
is permitted above the SCAN operator.
NARY NESTED LOOP JOIN execution
has a performance benefit over the execution of a series of NESTED
LOOP JOIN operators. The example below demonstrates a
fundamental difference between the two methods of execution.
With a series of NESTED LOOP JOIN,
a scan may eliminate rows based on searchable argument values initialized
by an earlier scan. That scan may not be the one that immediately
preceded the failing scan. With a series of NESTED LOOP
JOINs, the previous scan would be completely
drained although it has no effect on the failing scan. This could
result in a significant amount of needless I/O. With NARY
NESTED LOOP JOINs, the next row fetched comes from
the scan that produced the failing searchable argument value, which
is far more efficient.
select a.au_id, au_fname, au_lname from titles t, titleauthor ta, authors a where a.au_id = ta.au_id and ta.title_id = t.title_id and a.au_id = t.title_id and au_lname = "Bloom"
QUERY PLAN FOR STATEMENT 1 (at line 1). STEP 1 The type of query is SELECT. 4 operator(s) under root |ROOT:EMIT Operator (VA = 4) | | |N-ARY NESTED LOOP JOIN Operator (VA = 3) has 3 children. | | | | | SCAN Operator (VA = 0) | | | FROM TABLE | | | authors | | | a | | | Table Scan. | | | Forward Scan. | | | Positioning at start of table. | | | Using I/O Size 2 Kbytes for data pages. | | | With LRU Buffer Replacement Strategy for data pages. | | | |SCAN Operator (VA = 1) | | | FROM TABLE | | | titleauthor | | | ta | | | Table Scan. | | | Forward Scan. | | | Positioning at start of table. | | | Using I/O Size 2 Kbytes for data pages. | | | With LRU Buffer Replacement Strategy for data pages. | | | | | SCAN Operator (VA = 2) | | | FROM TABLE | | | titles | | | t | | | Index : titles_6720023942 | | | Forward Scan. | | | Positioning by key. | | | Index contains all needed columns. Base table will not be read. | | | Keys are: | | | title_id ASC | | | Using I/O Size 2 Kbytes for index leaf pages. | | | With LRU Buffer Replacement Strategy for index leaf pages.
Figure 2-3 depicts
a series of NESTED LOOP JOINs.
Figure 2-3: Emit operator tree with Nested loop joins
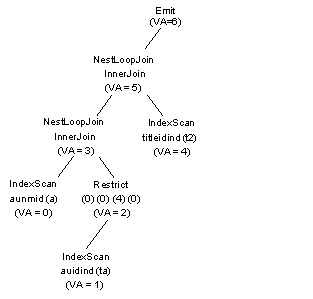
All query processor operators are assigned a virtual address.
The lines in Figure 2-3 with VA = report
the virtual address for a given operator.
The effective join order is authors, titleauthor, titles.
A RESTRICT operator is
the parent operator of the scan on titleauthors.
This plan is transformed into the NARY NESTED
LOOP JOIN plan below:
Figure 2-4: NARY NESTED LOOP JOIN operator
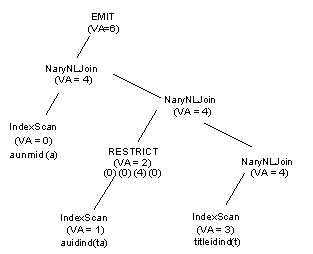
The transformation retains the original join order of authors, titleauthor,
and titles. In this example, the scan of titles has
two searchable arguments on it—ta.title_id = t.title_id and a.au_id = t.title_id.
So, the scan of titles fails because of the
searchable argument value established by the scan of titleauthor, or
it fails because of the searchable argument value established by
the scan of authors. If no rows are returned
from a scan of titles because of the searchable
argument value set by the scan of authors,
there is no point in continuing the scan of titleauthor.
For every row fetched from titleauthor, the
scan of titles fails. It is only when a new
row is fetched from authors that the scan of titles might succeed.
This is why NARY NESTED LOOP JOINs have
been implemented; they eliminate the useless draining of tables
that have no impact on the rows returned by successive scans.
In the example, the NARY NESTED LOOP JOIN operator
closes the scan of titleauthor, fetches a new
row from authors, and repositions the scan
of titleauthor based on the au_id fetched
from authors. Again, this can be a significant
performance improvement as it eliminates the needless draining of the titleauthor table
and the associated I/O that could occur.
