![]()
![]()
![]()
![]()
A clustered index partition scan uses multiple worker processes to scan data pages in a partitioned table when the clustered index key matches a search argument. This method can be used only on allpages-locked tables.
One worker process is assigned to each partition in the table. Each worker process accesses data pages in the partition, using one of two methods, depending on the range of key values accessed by the process. When a partitioned table has a clustered index, rows are assigned to partitions based on the clustered index key.
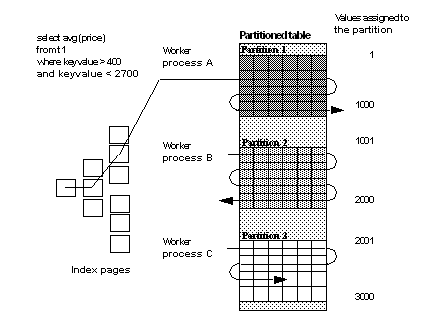
Figure 25-2 shows a clustered index partition scan that spans three partitions. Worker processes A, B, and C are assigned to each of the table’s three partitions. The scan involves two methods:
Method 1
Worker process A traverses the clustered index to find the first starting page that satisfies the search argument, about midway through partition 1. It then begins scanning data pages until it reaches the end of partition 1.
Method 2
Worker processes B and C do not use the clustered index, but, instead, they begin scanning data pages from the beginning of their partitions. Worker process B completes scanning when it reaches the end of partition 2. Worker process C completes scanning about midway through partition 3, when the data rows no longer satisfy the search argument.
Figure 25-2: Parallel clustered index partition scan