![]()
![]()
![]()
![]()
Adaptive Server uses a coordinating process and multiple worker processes to execute queries in parallel. A query that runs in parallel with eight worker processes is much like eight serial queries accessing one-eighth of the table, with the coordinating process supervising the interaction and managing the process of returning results to the client. Each worker process uses approximately the same amount of memory as a user connection. Each worker process runs as a task that must be scheduled on an engine, scans data pages, queues disk I/Os, and performs in many ways like any other task on the server. One major difference is that in last phase of query processing, the coordinating process manages merging the results and returning them to the client, coordinating with worker processes.
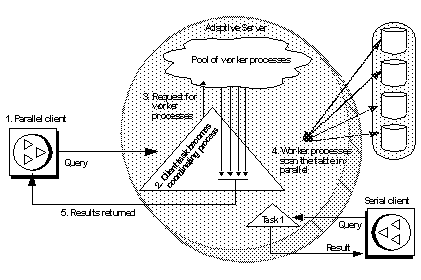
Figure 24-1 shows the events that take place during parallel query processing:
The client submits a query.
The client task assigned to execute the query becomes the coordinating process for parallel query execution.
The coordinating process requests four worker processes from the pool of worker processes. The coordinating process together with the worker processes is called a family.
The worker processes execute the query in parallel.
The coordinating process returns the results produced by all the worker processes.
The serial client shown in the lower-right corner of Figure 24-1 submits a query that is processed serially.
Figure 24-1: Worker process model
During query processing, the tasks are tracked in the system tables by a family ID (fid). Each worker process for a family has the same family ID and its own unique server process ID (spid). System procedures such as sp_who and sp_lock display both the fid and the spid for parallel queries, allowing you to observe the behavior of all processes in a family.
