![]()
![]()
![]()
![]()
Replication Server allows you to partition transactions for each connection according to one or more of these attributes:
Origin
Origin and session ID
None, in which no partitioning rule is applied
User name
Origin begin and commit times
Transaction name
![]() If partitioning rules are to be used to improve performance,
dsi_serialization_method must
not be wait_for_commit. wait_for_commit removes
contention by reducing parallelism.
If partitioning rules are to be used to improve performance,
dsi_serialization_method must
not be wait_for_commit. wait_for_commit removes
contention by reducing parallelism.
To select partition rules, use the alter connection command with the dsi_partitioning_rule option. The syntax is:
alter connection to data_server.database
set dsi_partitioning_rule to ‘{ none|rule[, rule ] }’
Values for rule are user, time, origin, origin_sessid, and name.For example, to partition transactions according to user name and origin begin and commit times, enter:
alter connection to TOKYO_DS.pubs2 set dsi_partitioning_rule to ‘user,time’
origin causes transactions from the same origin to be serialized when applied to the replicate database .
origin_sessid causes transactions
with the same origin and the same process
ID to be serialized when applied to the replicate database. Sybase
recommends that when first trying partitioning rules start with
a setting of origin_sessid,time.
![]() The process ID for Application Server is the Session
Process ID (SPID).
The process ID for Application Server is the Session
Process ID (SPID).
none is the default behavior, in which the DSI scheduler assigns each transaction group or large transaction to the next available parallel DSI thread.
If you choose to partition transactions according to user name, transactions entered by the same primary database user ID are processed serially. Only transactions entered by different user IDs are processed in parallel.
Use of this partitioning rule avoids contentions, but may in some cases cause unnecessary loss of parallelism. For example, consider a DBA who is running multiple batch jobs. If the DBA submits each batch job using the same user ID, Replication Server processes each one serially.
The user name partitioning rule is most useful if each user connection at the primary has a unique ID. It is less useful if multiple users log on using the same ID, such as “sa.”
If the time partitioning rule is used, the DSI scheduler looks at the origin begin and commit times of transactions to determine which transactions could not have been executed by the same process at the primary database. A transaction whose origin begin time is earlier than the commit time of the preceding transaction can be processed by a different DSI executor thread.
Suppose the origin begin and commit times partitioning rule has been selected, and the transactions and processing times shown in Figure 4-6 are all from the same primary database.
Figure 4-6: Transaction origin begin and commit times
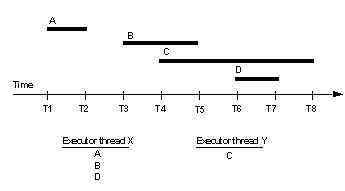
In this example, the DSI scheduler gives transaction A to DSI executor thread X. The scheduler then compares the begin time of transaction B and the commit time of transaction A. As transaction A has committed before transaction B begins, the scheduler gives transaction B to executor thread X. That is, transactions A and B may be grouped together and may be processed by the same DSI executor thread. Transaction C, however, begins before transaction B commits. Therefore, the scheduler assumes that transactions B and C were applied by different processes at the primary, and gives transaction C to executor thread Y. Transactions B and C are not allowed in the same group and may be processed by different DSI executor threads. Because transaction D begins before transaction C commits, the scheduler can safely give transaction D to executor thread X.
![]() Use of the origin begin and commit times partitioning
rule may lead to contentions when large transactions are processed,
as they are scheduled before the commits are seen.
Use of the origin begin and commit times partitioning
rule may lead to contentions when large transactions are processed,
as they are scheduled before the commits are seen.
The DSI scheduler can use transactions names to group transactions for serial processing. When creating a transaction on Adaptive Server, you can use the begin transaction command to assign a transaction name.
If the transaction name partitioning rule is applied, the DSI scheduler assigns transactions with the same name to the same executor thread. Transactions with different transaction names are processed in parallel. Transactions with a null or blank name are ignored by the name parameter. Their processing is determined by other DSI parallel processing parameters or the availability of other executor threads.
![]() This partitioning rule is available to non-Sybase data
servers only if they support transaction names.
This partitioning rule is available to non-Sybase data
servers only if they support transaction names.
By default, Adaptive Server always assigns a name to each transaction. If a name has not been assigned explicitly using begin transaction, Adaptive Server assigns a name that begins with the underscore character and includes additional characters that describe the transaction. For example, Adaptive Server assigns a single insert command the default name “_ins.”
Use the dsi_ignore_underscore_name option with alter connection to specify whether or not Replication Server ignores these names when partitioning transactions based on transaction name. By default, dsi_ignore_underscore_name is on, and Replication Server treats transactions with names that begin with an underscore in the same way it treats transactions with null names.
