![]()
![]()
![]()
![]()
Use parallel bulk copy to copy data in parallel to a specific partition. Parallel bulk copy substantially increases performance during bcp sessions because it can split large bulk copy jobs into multiple sessions and run the sessions concurrently.
To use parallel bulk copy:
The destination table must be partitioned.
Use sp_helpartition to see the number of partitions on the table.
Use alter table ... partition to partition the table, if the table is not already partitioned.
The destination table should not contain indexes because:
If the table has a clustered index, this index determines the physical placement of the data, causing the partition specification in the bcp command to be ignored.
If any indexes exist, bcp automatically uses its slow bulk copy instead of its fast bulk copy mode.
If nonclustered indexes exist on the tables, parallel bulk copy is likely to lead to deadlocks on index pages.
Each partition should reside on a separate physical disk for the best performance.
Before you copy data into your database, you must partition the table destined to contain the data.
Parallel bulk copy can copy in to a table from multiple operating system files. To do so, use:
bcp tablename :partition_number in file_name
Figure 3-1 illustrates the parallel bulk copy process.
Figure 3-1: Copying data into a partitioned table using parallel bulk copy
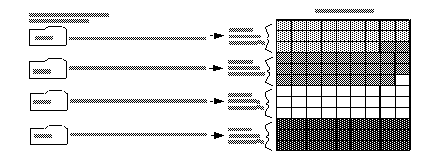
See the Adaptive Server Enterprise Performance and Tuning Guide for information about partitioning a table.
![]() When using parallel bulk copy to copy data out, you
cannot specify which partitions bcp should use.
When using parallel bulk copy to copy data out, you
cannot specify which partitions bcp should use.
