![]()
![]()
![]()
![]()
A range query that returns a small number of rows performs well with the index, however, range queries that return a large number of rows may not use the index—it may be more expensive to perform the logical and physical I/O for a large number of index pages plus a large number of data pages. The lower the data row cluster ratio, the more expensive it is to use the index.
At the leaf level of a nonclustered index or a clustered index on a data-only-locked table, the keys are stored sequentially. For a search argument on a value that matches 100 rows, the rows on the index leaf level fit on perhaps one or two index pages. The actual data rows might all be on different data pages. The following queries show how different data row cluster ratios affect I/O estimates. The authors table uses datarows locking, and has these indexes:
A clustered index on au_lname
A nonclustered index on state
Each of these queries returns about 100 rows:
select au_lname, phone from authors where au_lname like "E%"
select au_id, au_lname, phone from authors where state = "NC"
The following table shows the data row cluster ratio for each index, and the optimizer’s estimate of the number of rows to be returned and the number of pages required.
SARG on |
Data row cluster ratio |
Row estimate |
Page estimate |
Data I/O size |
au_lname |
.999789 |
101 |
8 |
16K |
state |
.232539 |
103 |
83 |
2K |
The basic information on the table is:
The table has 262 pages.
There are 19 rows per data page in the table.
While each of the queries has its search clauses in valid search-argument form, and each of the clauses matches an index, only the first query uses the index: for the other query, a table scan is cheaper than using the index. With 262 pages, the cost of the table scan is:
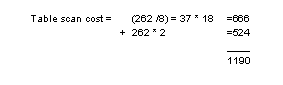
Looking more closely at the tables, cluster ratios, and search arguments explains why the table scan is chosen:
The estimate for the clustered index on au_lname includes just 8 physical I/Os:
6 I/Os (using 16K I/O) on the data pages, because the data row cluster ratio indicates very high clustering.
2 I/Os for the index pages (there are 128 rows per leaf page); 16K I/O is also used for the index leaf pages.
The query using the search argument on state has to read many more data pages, since the data row cluster ratio is low. The optimizer chooses 2K I/O on the data pages. 83 physical I/Os is more than double the physical I/O required for a table scan (using 16K I/O).
