![]()
![]()
Chapter 11 Reverse engineering d'une base de données dans un MPD
Si le code sur lequel vous souhaitez effectuer un reverse engineering contiennent des fichiers sources écrits avec Unicode ou MBCS (Multibyte Character Set), vous devez utiliser les paramètres de codage mis à votre disposition dans la zone Codage de fichier.
Si vous souhaitez changer ces paramètres car vous savez quel codage est utilisé dans les sources, cliquez sur le bouton Points de suspension en regard de la zone Codage de fichier pour sélectionner le paramètre de codage approprié. Vous affichez ainsi la boîte de dialogue Format de codage pour le texte en entrée qui permet de sélectionner le type de codage de votre choix.
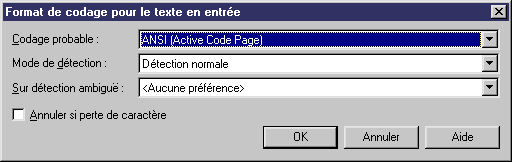
La boîte de dialogue Format de codage pour le texte en entrée inclut les propriétés suivantes :
| Propriété | Description |
|---|---|
| Codage probable | Format de codage à utiliser comme codage probable lors du reverse engineering du fichier. |
| Mode de détection | Indique si la détection de codage de texte doit être tentée et spécifie la quantité de chaque fichier qui doit être analysée. Lorsque cette option est activée, PowerAMC analyse une portion donnée au début du texte et, à partir d'une heuristique basée sur des séquences d'octets illégales dans les divers codages possibles et/ou la présence de certaines balises permettant d'identifier le codage, il essaie de détecter le codage approprié à utiliser pour la lecture du texte.
La valeurs suivantes sont disponibles :
|
| Sur détection ambiguë | Spécifie le type d'action à entreprendre en cas d'ambiguïté. La valeurs suivantes sont disponibles :
|
| Annuler si perte de caractère | Permet d'arrêter le reverse engineering si des caractères ne peuvent pas être identifiés et risquent d'être perdus lors du codage de fichier. |
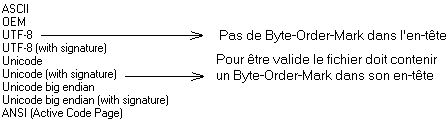
Voici un exemple de lecture de formats de codage dans la liste :
| Copyright (C) 2008. Sybase Inc. All rights reserved. |
| |