![]()
![]()
![]()
![]()
You have a number of choices when creating a data pipeline. This section leads you through them.
![]() To create a data pipeline:
To create a data pipeline:
Click the New button in the PowerBar and then select the Database tab page.
Select Data Pipeline and click OK.
The New Data Pipeline dialog box displays.
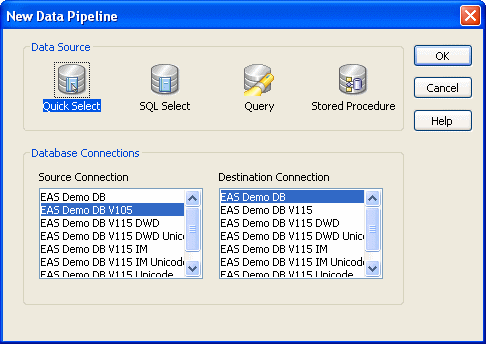
The Source Connection and Destination Connection boxes display database profiles that have been defined. The last database you connected to is selected as the source. The first database on the destination list is selected as the destination.
![]() If you do not see the connections you need
To create a pipeline, the databases you want to use for your
source and destination must each have a database profile defined.
If you do not see profiles for the databases you want to use, select
Cancel in the New Data Pipeline dialog box and then define those
profiles. For information about defining
profiles, see “Changing the destination and source databases”.
If you do not see the connections you need
To create a pipeline, the databases you want to use for your
source and destination must each have a database profile defined.
If you do not see profiles for the databases you want to use, select
Cancel in the New Data Pipeline dialog box and then define those
profiles. For information about defining
profiles, see “Changing the destination and source databases”.
Select a data source.
The data source determines how InfoMaker retrieves data when you execute a pipeline:
Data source |
Use it if |
|---|---|
Quick Select |
The data is from tables that have a primary/foreign key relationship and you need only to sort and limit data |
SQL Select |
You want more control over the SQL SELECT statement generated for the data source or your data is from tables that are not connected through a key |
Query |
The data has been defined as a query |
Stored Procedure |
The data is defined in a stored procedure |
Select the source and destination connections and click OK.
Define the data to pipe.
How you do this depends on what data source you chose in step 3, and is similar to the process used to define a data source for a report. For complete information about using each data source and defining the data, see Chapter 5, “Defining Reports.”
When you finish defining the data to pipe, the Data Pipeline painter workspace displays the pipeline definition, which includes a pipeline operation, a check box for specifying whether to pipe extended attributes, and source and destination items.
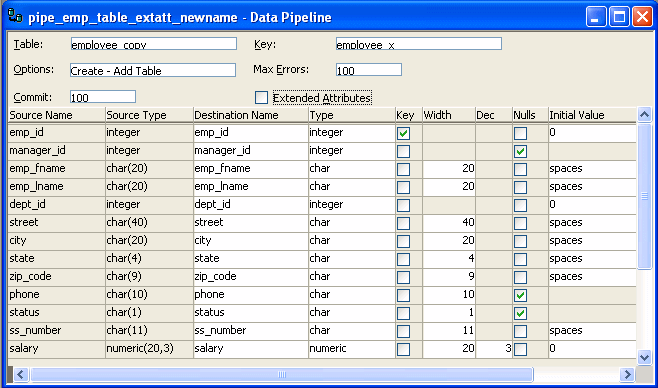
The pipeline definition is InfoMaker’s best guess based on the source data you specified.
Modify the pipeline definition as needed.
For information, see “Modifying the data pipeline definition”.
(Optional) Modify the source data as needed. To do so, click the Data button in the PainterBar, or select Design>Edit Data Source from the menu bar.
For information about working in the Select painter, see Chapter 5, “Defining Reports.”
When you return to the Data Pipeline painter workspace, InfoMaker reminds you that the pipeline definition will change. Click OK to accept the definition change.
If you want to try the pipeline now, click the Execute button or select Design>Execute from the menu bar.
InfoMaker retrieves the source data and executes the pipeline. If you specified retrieval arguments in the Select painter, InfoMaker first prompts you to supply them.
![]() The role of the Query governor
Options you set in the Query Governor affect the Data Pipeline
painter when you specify the data and when data is piped. In the
Query Governor, you can set data selection options and limit the
number of rows piped and the elapsed piping time.
The role of the Query governor
Options you set in the Query Governor affect the Data Pipeline
painter when you specify the data and when data is piped. In the
Query Governor, you can set data selection options and limit the
number of rows piped and the elapsed piping time.
For more information, see Chapter 2, “Working with Libraries.”
At runtime, the number of rows read and written, the elapsed execution time, and the number of errors display in MicroHelp. You can stop execution yourself or InfoMaker might stop execution if errors occur.
For information about execution and how rows are committed to the destination table, see “When execution stops”.
Save the pipeline definition if appropriate.
For information, see “Saving a pipeline”.
